REST has served us well for more than a decade as the de facto architectural style for our HTTP APIs but it is starting to show its age. It may still be relevant if you are not only the provider but also the (sole?) consumer of your API. In such situation, you can use pretty much anything you want since you know what you have on the back-end and what you want for the front-end.
REST can be nice for simple APIs but as your project grows, it becomes more and more complex to make your API work with REST principles. Let’s consider a simple example, with two concepts: Movies and Actors. An actor has appeared in multiple movies and a movie is realized with multiple actors. A simple REST API for those concepts may look like this:
/movies- list all movies/movies/:movieId- details of a movie/movies/:movieId/actors- list all actors in a movie/actors- list all actors/actors/:actorId- details of an actor/actors/:actorId/movies- list all movies of an actor
Now let’s consider that, as an unknown consumer of this API, I want to create the following page. For one specific actor, here Christian Bale, I want to see the list of the actors and actresses that he worked with.
{kind=link}
How can I create this page? How many requests do I need to make? How much useless information will I have to download? For this short exercice, we will consider that Christian Bale has been involved in 50 movies with 20 actors each.
We could start with a request to retrieve some information about him (1 request)
https://localhost/actors/christianbale
{
"name": "Christian Bale",
"born" : 1974,
"movies": "https://localhost/actors/christianbale/movies",
}
then we could have to retrieve the list of all his movies (1 request)
https://localhost/actors/christianbale/movies
[
{
"href": "http://localhost/movies/thedarkknight"
},
{
"href": "http://localhost/movies/americanpsycho"
}
]
from there we would need a request per movie to find the details of each movie (50 requests)
https://localhost/movie/thedarkknight
{
"name": "The Dark Knight",
"releaseYear": 2008,
"actors": "http://localhost/movies/thedarkknight/actors",
"script": "...",
"feedback": [
...
]
}
then I need one more request per movie to find the actors involved in those movies (50 requests)
https://localhost/movies/thedarkknight/actors
[
{
"href": "http://localhost/actors/heathledger"
},
{
"href": "http://localhost/actors/michaelcaine"
}
]
Finally for each of those actors I would need to make a final request to have some details like their name and profile picture (20 * 50 requests).
I just need to retrieve a list of a thousand names and I would need more than a thousand independant HTTP requests. The time taken by all those requests would be mind-blowing and this is just to navigate a simple graph composed of two kinds of entities.
Improvements?
We could start to improve the situation by hardcoding some URLs in the clients. With such an improvement, we would remove the support for hypermedia to move back to hardcoded endpoints and manual discovery of the REST API. We could also return more information at once, for example, when asking for an actor we could also return the list of all his movies. As a consequence, if someone only want the birth place of an actor he will also have a lot of useless data. We could also provide more information in the responses of collections like the name of the actors and movies. Where do we stop? How do we maintain a different set of properties for the same entity depending on the endpoint?
Of course, if we knew beforehand that our clients wanted to create this page, we could build a custom made API for this and most of those issues would go away. Even then, do we really want to maintain a custom endpoint for each need? Do you know what you are going to need tomorrow? It is very complex and time-consuming to ensure the consistency of such a solution. In the end, a generic REST API it not an efficient way to navigate a graph of data.
GraphQL is a query language for APIs created by Facebook. It has been deployed in production for several years at Facebook and more recently at Github and others. With GraphQL, consumers of an API can ask exactly for what they need and they will receive what they have asked, nothing more.
With a GraphQL API, the provider defines the API as a schema of interconnected types with fields. There is only one endpoint simplifying the discovery of the API. Since the schema of the API is typed, the tooling of your developers can be configured from those types to provide code completion and validation. You can also easily create a consistent API more easily since you won’t create multiple endpoints showing the same entities with different sets of properties depending on the endpoint.
On top of that, most GraphQL frameworks are able to parse and validate the syntax of the queries automatically. GraphQL is network agnostic so you can use it over HTTP, WebSocket or even without any network at all. In a similar fashion, it does not define any serialization strategy, yet with most GraphQL frameworks, it is very easy to serialize the result of a query in JSON.
GraphQL follows a precise specification which defines its language, its type system, its validation strategy and even its error format.
Queries
In order to let your users run GraphQL queries, you have to start by defining the schema of your API. A very simple GraphQL schema can look like this:
type Query {
viewer: User
}
type User {
username: String
}
In a schema, the type Query is the entry point of all the queries. From there, in this example, we can navigate to the type User using the field viewer and ask for the username of the User. We could send the following GraphQL query to retrieve our username:
{
viewer {
username
}
}
Thanks to this query, we would retrieve the following data (once serialized in JSON):
{
"viewer": {
"username": "John Doe"
}
}
As you can see, the shape of the query will determine the shape of the result.
Fields can either return Scalars or Objects, if a field returns an object (like the field viewer in the example before) you have to make a sub-selection to retrieve some of its properties. Using a schema defining the concept of Movie and Actor, we could retrieve a movie and its actors using the following query:
{
movie {
name
actors {
name
}
}
}
This query would produce the following result:
{
"movie": {
"name": "The Dark Knight",
"actors": [
{ "name": "Christian Bale" },
{ "name": "Heath Ledger" },
{ "name": "Aaron Eckhart" },
{ "name": "Michael Caine" },
{ "name": "Maggie Gyllenhaal" },
{ "name": "Gary Oldman" },
{ "name": "Morgan Freeman" },
{ "name": "Monique Gabriela Curnen" },
{ "name": "Ron Dean" },
{ "name": "Cillian Murphy" }
]
}
}
In this situation, since the field actors returns a list, the fields requested are requested on each element of the list.
Arguments
You also have the ability to give arguments to the fields of your query to change the result. Each field can have its own specific set of argument instead of a common set of arguments in the query part of the URL of a REST API.
{
movie(id: "1000") {
name
actors(kind: WOMAN) {
name
}
}
}
Here the argument id is used to select a specific movie while the argument kind can be used to filter the actors returned. We may thus obtain the following result for this query:
{
"movie": {
"name": "The Dark Knight",
"actors": [
{ "name": "Maggie Gyllenhaal" },
{ "name": "Monique Gabriela Curnen" }
]
}
}
Aliases
Since the schape of the query determines the structure of the response, we can encounter some conflicts. In order to solve this issue, you can use aliases. Here, we want to retrieve two movies at once and to prevent any issue, we can assign an alias to rename each movie.
{
thedarkknight: movie(id: "1000") {
name
}
americanpsycho: movie(id: "1300") {
name
}
}
We can see that the structure of the JSON response uses thedarkknight and americanpsycho instead of two occurrences of the field movie which would produce an invalid response.
{
"thedarkknight": {
"name": "The Dark Knight"
},
"americanpsycho": {
"name": "American Psycho"
}
}
Fragments
If you want to retrieve multiple entities of the same kind, you may want to always retrieve the same set of fields from those entities. In the previous example, we asked for two movies and we had to repeat the fields requested from those movies.
With GraphQL you can use a fragment to define a specific set of fields to retrieve on a type. Then you can use this fragment in other parts of your query. In the example below, you can see that we want to retrieve, for both movies, their name and the name of their actors.
{
thedarkknight: movie(id: "1000") {
...movieFields
}
americanpsycho: movie(id: "1300") {
...movieFields
}
}
fragment movieFields on Movie {
name
actors {
name
}
}
With fragments, you can write complex queries much more easily.
Dynamic arguments
GraphQL offers the support of dynamic arguments in order to let you define a query which can be reused with various arguments. This way you won’t have to concatenate pieces of queries with user-provided parameters to create your GraphQL query. This would prevent GraphQL injection security issues by sanitizing the arguments provided.
query movieAndActors($id: String) {
movie(id: $id) {
name
actors {
name
}
}
}
A query can also have a name, here movieAndActors, in order to let you log some information more easily for example.
Mutations
Queries are only used in order to request some data from a server, they are not supposed to produce any side effect just like GET requests.
If you want to modify the state of the server, you have to use a Mutation. Mutations are similar to queries but they will use the arguments supplied to change things, for example here, to create a new movie. A mutation will also define the shape of the response returned once the operation has been performed. Here, I want to create a new movie and to retrieve its name along with the name of its actors.
mutation {
createMovie(name: "Captain Marvel") {
name
actors {
name
}
}
}
In this situation, the newly created movie is empty but it could have been initialized with some data.
{
"createMovie": {
"name": "Captain Marvel",
"actors": []
}
}
There is another key difference between queries and mutations, queries may be executed in parallel while mutation will be executed one after the other. You could thus send the following mutation to a server which would create a movie, and some actors.
mutation {
createMovie(name: "Captain Marvel") {
name
}
createActor(movieName: "Captain Marvel", name: "Brie Larson") {
name
}
createActor(movieName: "Captain Marvel", name: "Lee Pace") {
name
}
createActor(movieName: "Captain Marvel", name: "Samuel L. Jackson") {
name
}
}
Schema
In order to define you GraphQL schema, you have the ability to use the API of a GraphQL framework for you favorite programming language or you can use the schema definition language (SDL) which defines a textual representation of the Graphql schema. The first version of a GraphQL schema would look like this.
schema {
query: Query
}
type Query {
}
In this basic schema, the entry point Query is defined but it does not contain any field. We can create new types and fields used to connect all those types together.
schema {
query: Query
}
type Query {
actor: Actor
}
type Actor {
name: String
}
The fields can return another object, like in the field actor, or a scalar. There are multiple scalars available by default in GraphQL including String, Boolean and Int. It is also possible to define a field returning a list of entities with brackets.
schema {
query: Query
}
type Query {
actor: Actor
actors: [Actor]
}
type Actor {
name: String
}
You can mark a field as non-nullable with a ! and you can also use it to indicate a non-nullable list of non-nullable entities. In this case, while requesting an unknown actor will return nothing, asking for all the actors will at least return an empty list.
schema {
query: Query
}
type Query {
actor: Actor
actors: [Actor!]!
}
type Actor {
name: String!
}
We could build a GraphQL API to manipulate actors and movies using the following schema. Additional fields and arguments have been added to provide a more useful API.
schema {
query: Query
}
type Query {
actor(name: String!): Actor
actors: [Actor!]!
movie(name: String!): Movie
movies: [Movie!]!
}
type Actor {
name: String!
movies: [Movie!]!
}
type Movie {
name: String!
actors: [Actor!]!
}
In order to retrieve all the actors who have made a movie with Christian Bale, we could send the following query:
{
actor(name: "Christian Bale") {
name
movies {
name
actors {
name
}
}
}
}
And it would give us the following result (with way more movies and actors):
{
"actor": {
"name": "Christian Bale",
"movies": [
{
"name": "The Dark Knight",
"actors": [
{ "name": "Christian Bale" },
{ "name": "Heath Ledger" },
{ "name": "Aaron Eckhart" },
{ "name": "Michael Caine" },
{ "name": "Maggie Gyllenhaal" },
{ "name": "Gary Oldman" },
{ "name": "Morgan Freeman" },
{ "name": "Monique Gabriela Curnen" },
{ "name": "Ron Dean" },
{ "name": "Cillian Murphy" }
]
},
{
"name": "American Psycho",
"actors": [
{ "name": "Christian Bale" },
{ "name": "Jared Leto" },
{ "name": "Reese Witherspoon" },
{ "name": "Willem Dafoe" }
]
},
{
"name": "The Prestige",
"actors": [
{ "name": "Hugh Jackman" },
{ "name": "Christian Bale" },
{ "name": "Michael Caine" },
{ "name": "Piper Perabo" }
]
}
]
}
}
Just like with the REST version, this API could be improved with support for pagination. This GraphQL API gives us access to one/all movies and one/all actors from the query entry point. It also provides us with a way to nagitate from actors to movies and vice versa as such we can easily create a query retrieving all actors involved in a movie with Christian Bale.
While the response may be a bit long, we will not receive a massive amount of useless data and we won’t have to make hundreds of HTTP requests over the network to do so. Just like with a REST API, if we knew that our users needed this feature, we could provide it directly in our GraphQL API with a field colleagues on actors for example.
type Actor {
name: String!
movies: [Movie!]!
colleagues: [Actor!]!
}
The GraphQL type system is very powerful and there are tons of other features available in GraphL with interfaces, union types and much more. The official website also provides various strategies to implement some pagination.
You can inspect the concepts available in a GraphQL schema using the introspection capabilities with the field __schema. With this field, you will have access to the GraphQL schema. Here is a simple query to find out the name of all the types in a GraphQL schema.
{
__schema {
types {
name
}
}
}
For more information, you could use a moce complex introspection query like this one:
query {
__schema {
queryType { name }
mutationType { name }
subscriptionType { name }
types {
...typeDetails
}
}
}
fragment typeDetails on __Type {
kind
name
description
fields(includeDeprecated: true) {
name
description
args {
...inputValueDetails
}
type {
...typeReferenceDetails
}
isDeprecated
deprecationReason
}
inputFields {
...inputValueDetails
}
interfaces {
...typeReferenceDetails
}
enumValues(includeDeprecated: true) {
name
description
isDeprecated
deprecationReason
}
possibleTypes {
...typeReferenceDetails
}
}
fragment inputValueDetails on __InputValue {
name
description
defaultValue
type {
...typeReferenceDetails
}
}
fragment typeReferenceDetails on __Type {
kind
name
ofType {
kind
name
ofType {
kind
name
ofType {
kind
name
}
}
}
}
You can find an introspection query in the JavaScript version of the GraphQL project and you can use it to pretty print any GraphQL schema with the following piece of code.
const fetch = require("node-fetch");
const { introspectionQuery, buildClientSchema, printSchema } = require("graphql");
const fs = require("fs");
const url = 'http://localhost:8080/api/graphql';
fetch(url, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query: introspectionQuery })
})
.then(res => res.json())
.then(res => {
const introspectionSchemaResult = JSON.parse(res.data);
const graphqlSchemaObj = buildClientSchema(introspectionSchemaResult);
const sdlString = printSchema(graphqlSchemaObj);
console.log(sdlString);
});
Tooling
{kind=link}
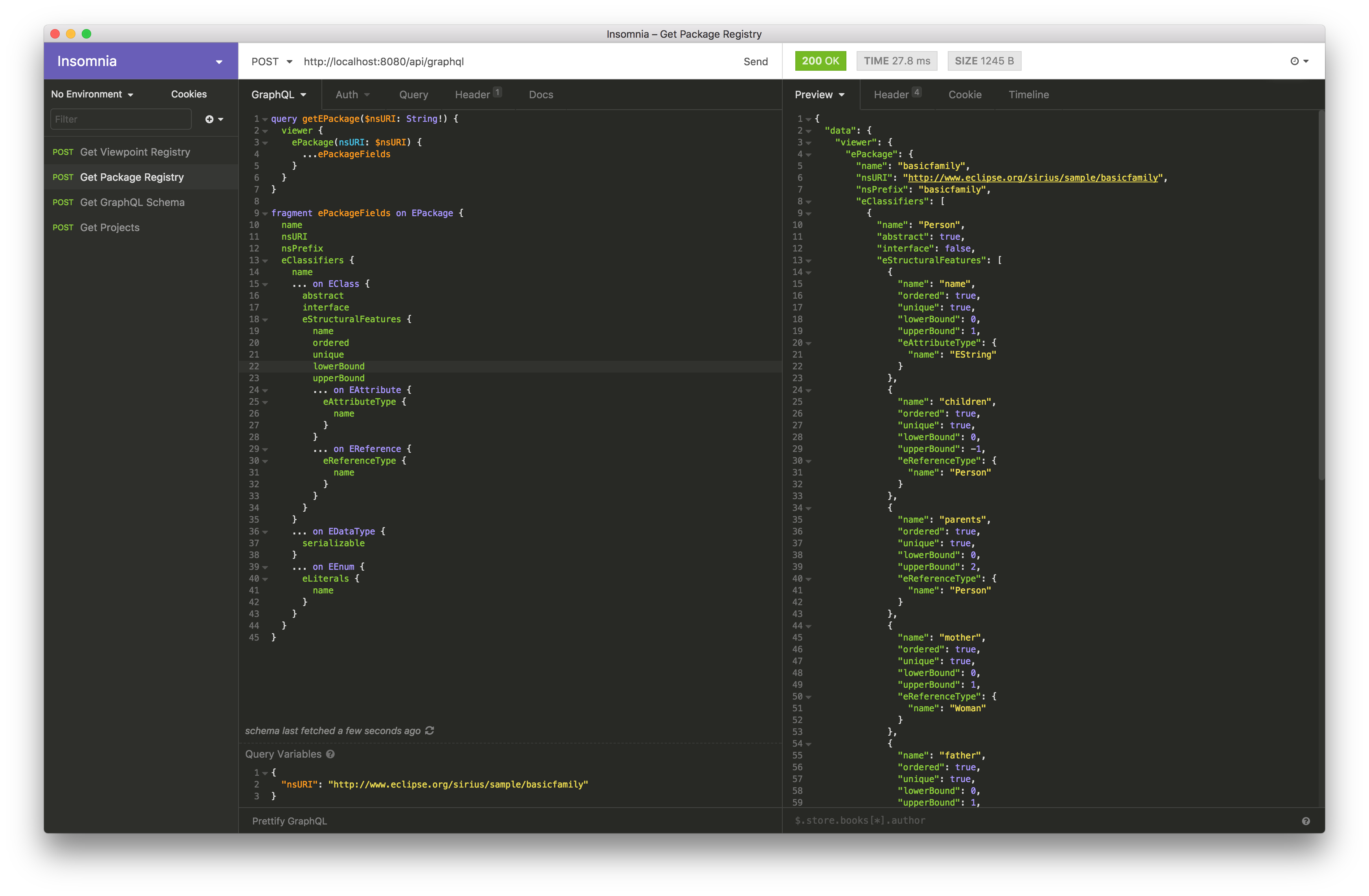
In order to setup and test your GraphQL queries, you should have a look at GraphiQL and Insomnia. Both tools are parameterized by the schema of the GraphQL endpoint that you want to call and they will provide some tooling with a great developer experience to help you write your queries.
To find more about GraphQL, follow me on twitter or come and see me at EclipseCon Europe 2018 in Germany where I will talk about the GraphQL API that we have created for our open source project, Eclipse Sirius.