This article is the second part of a series focusing on metamodel design (more especially Ecore models). Following the first part focused on some ground rules this second part is focused on slightly more technical aspects: scalability and Java. The general disclaimer still applies:
Most of the checks stated here are very easy to comply with when considered from the start but might not be that cheap later on. Furthermore this list is not exhaustive and not necessary the unique and unviversal truth. Your mileage may vary but then tell me about it!
Scalability
The design of your Ecore model has scalability and performances implications, most especially memory and I/O wise but not only. If you want to get the most of Eclipse Modeling technologies in general you should check the following items.
☑ Instances which will be present a lot in the models have a concise serialization
Ask yourself: how many instances of this EClass will I usually have in a model? If the answer is “quite a lot”(100K for instance) then check how they will be serialized and make sure there is not an improvement you could bring here.
This is particularly true when you use the XMI serialization which is not the most space efficient one and might need to add extra informations to clearly identify types for instance. This is also very true for custom datatypes. If this datatype is being used by a lot of instances then make sure your serialization logic which is coded through fromString() and toString() methods is concise.
☑ Everything which is serialized needs to be serialized
You need this model, but are there parts which have no need to be serialized? Can you strip out parts of the information? What information is actually captured by the users in opposition to the information which is infered by the tool? Is there any part of this data which has a shorter lifecycle than “load the file”/”save the file”? Are other elements referencing it ?
Those questions are useful to identify complete sub-graphs of the model which have no need to be serialized. You can’t get faster than not doing any work. That being said, if you need this information and recompute it each time you use the model, then it may not pay off.
☑ Derived features are fast, straightforward, or externalized
Using Ecore you can define derived features, often by hand-coding the Java logic. Tools and frameworks in the EMF eco-system are likely to access those features when reflectively discovering your model and generaly assume a CPU commplexity which is close to a field access: make sure the Java logic implementing it is fast and does not depend on some external framework being there. If it’s not the case it is better to expose it either as an EOperation (it will not be reflectively invoked), or defining a dedicated Java API.
☑ There is no EClass which could be replaced by an EDatatype
Any EClass used for an important number of instances should be inspected and a conscious decision should be made about whether it is best modeled as an EClass or as an EDatatype. Even with the EMF Ultra Slim Diet an EObject comes with an overhead, both in term of memory usage but even more importantly in the overhead framework code might induce (cross-referencers, change recorders..).
Rule of thumb: if you have many instances which will be never referenced by other instance beside the containing one and you don’t really need the individual change notifications of each attribute of the EObject, then it’s probably best to model it as an EDatatype. When an EClass only have EAttributes, no EReference and is not referenced by other objects besides its container it is also a clear indication that this might be a good candidate for being an EDatatype.
☑ The model has some structure
There are two main reasons to stay away from flat models with tens of thousands of instances in a single reference value:
for legacy reasons, EMF will check the uniqueness of any addition and as such in the Java implementation, a call to .add() will check for every item in the list. (there are way to explicitely avoid those checks by using addUnique()) displaying the reference content in the user interface will likely lead to the creation of tens of thousands of SWT items in a list or in a tree. SWT is not good at that and that might lead to long freezes.Sirius is kind enough to detect those situations and group such references, but you can’t count on that for every tree viewer.
{kind=link}
Cross-references modeled with EOpposites tend to introduce dependencies among several model files; transitively it quickly become impossible to load a file from the model without loading everything.
If what you aim for is scalability and performance the capability to focus on a subset of the model is a strong asset, as such you should avoid EOpposites references which would introduce inter-files relationships.
☑ The implementation classes are using MinimalEObjectImpl
Make sure your .genmodel is configured to leverage MinimalEObjectImpl. This is the default if you created your genmodel with a recent version of EMF, more information about this is available on Ed’s blog
Java
☑ Multiple inheritance is not over-used
Ecore allows for multiple inheritance. But in the end your Ecore model is transformed into Java code and Java only allows multiple interfaces to be implemented.
The EMF code generator hides that for you and might ends up duplicating code to make sure everything works as expected. A few things to keep in mind:
the order of the inheritance matters: the implementation class will extends the implementation class of the first EClass in the list of supertypes, the subsequent classes will lead to duplicated code. just like for Object Oriented designs, having a lot of multiple inheritance screams of a design which is not really splitting concerns (or not the right ones)☑ Custom DataType are used in every situation where it makes sense
EMF provides off-the-shelve datatypes for Strings, Integer, Float, Long and their primitive counterparts as EString, EInt …
{kind=link}
But String is a technical concern and it might make the design more evident to replace usages of EString by your own EDataType if it express a domain specific type, even if you keep it mapped to java.lang.String. It makes the Ecore model more explicit and paves the way for a behavior which can be specific to this particular type.
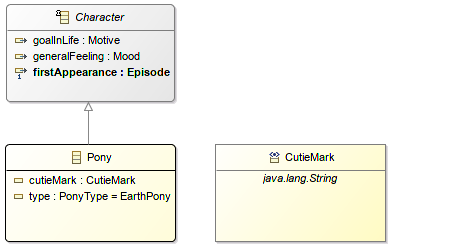{kind=link}
If your custom datatype is not mapped to a very standard Java type, then make sure your implementation is compliant with the equals/hashcode contract otherwise tools like EMF Compare will have no mean to compare those individual values.
☑ The .genmodel output folders are specified or made empty
A simple right-click, Generate All action on the genmodel should give the result you intend. Don’t rely on peoples knowing before-hand that you should only generate the model and edit plugin for instance. Don’t make them think about such things.
You can do so in making the corresponding [...] Directory properties empty in the genpackage instance.
{kind=link}
The editor will then adapt its contextual menu and Generate all will not launch the tests generation.
{kind=link}
Also it is generally better to use src-gen instead of src as the final folder, take the chance to update that at the same time.
{kind=link}
☑ The .genmodel base package is specified
Set the base package property in the .genmodel file as it drives your Java namespace. You should never introduce empty EPackages to get the Java namespace result you want but instead you should use the base package property.
{kind=link}
That’s it for now. If you start with this checklist you will have covered the basics.
My goal with EcoreTools is to assist you in taking care of those aspects, that’s why many of those rules are illustrated by specific features of this diagram editor. You will find this tool in the Eclipse Modeling Package and the EcoreTools website covers how to get started with it.
Give it a shot, it’s all Open-Source and part of Eclipse!
Credits: thanks to Pierre-Charles and Mélanie for the proof-reading, Jan for bringing a new item and Roxanne for some of the ponies.